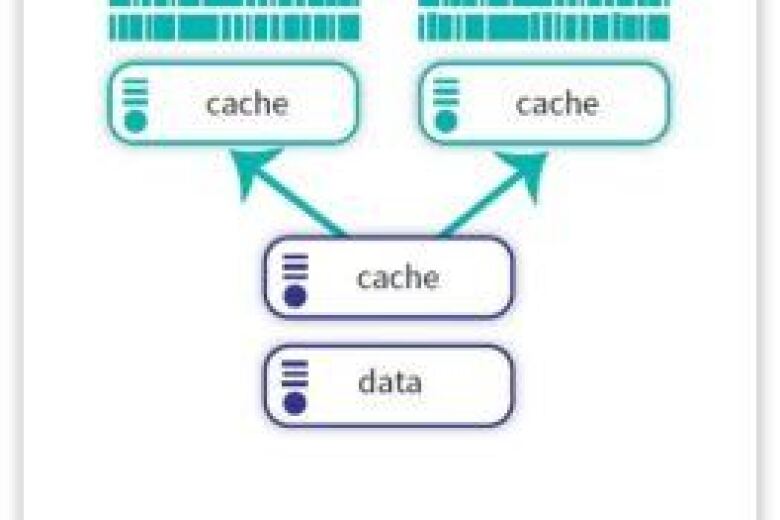
La fragmentación o sharding de bases de datos es un patrón de arquitectura en el que un gran conjunto de datos se divide en partes más pequeñas y manejables llamadas "fragmentos" ("shard" en inglés). Cada fragmento se almacena en un servidor de base de datos independiente para mejorar el rendimiento, la escalabilidad y la disponibilidad.
Este enfoque ayuda a distribuir la carga y garantiza que ningún servidor se convierta en un cuello de botella, lo que permite al sistema gestionar más datos y mayores volúmenes de transacciones de forma eficiente. Cada fragmento funciona de forma independiente, pero juntos forman un único sistema lógico de base de datos. Además, la fragmentación de bases de datos puede mejorar la tolerancia a fallos al aislar estos en fragmentos individuales, lo que permite que el resto del sistema siga funcionando sin problemas.
En este artículo, desglosaremos las ventajas de la fragmentación de bases de datos, cómo se compara con otros métodos de organización de bases de datos y cómo ayuda a mantener los datos seguros y accesibles.
Principales conclusiones
- La fragmentación de bases de datos mejora el tiempo de respuesta, la organización y el escalado de las empresas.
- A veces, esto se consigue a costa de una mayor complejidad y comisiones de mantenimiento más elevadas.
- La distribución eficaz de datos es una característica imprescindible para las empresas en el futuro.
Introducción a Database Sharding
Las empresas se enfrentan a una explosión de datos sin precedentes. El volumen, la velocidad y la variedad de la información que necesitan procesar y analizar crece a un ritmo exponencial cada año. Los estudios muestran que se espera que la cantidad de datos creados y replicados a nivel mundial casi se duplique entre 2021 y 2025, alcanzando la asombrosa cifra de 181 zettabytes (es decir, 181.000 millones de terabytes). Esta afluencia masiva de datos presenta tanto oportunidades como retos. Aunque ofrece la posibilidad de profundizar en el conocimiento y tomar decisiones más informadas, también ejerce una inmensa presión sobre los sistemas de bases de datos. A medida que crecen los volúmenes de datos, las arquitecturas tradicionales suelen tener dificultades para seguir el ritmo, lo que se traduce en tiempos de consulta más lentos, menor rendimiento y posibles fallos del sistema.
Aquí es donde entra en juego la fragmentación de bases de datos. Al distribuir los datos entre varios servidores, la fragmentación permite a las empresas escalarlas horizontalmente, manteniendo eficazmente el ritmo de las crecientes demandas de datos. Permite a las empresas mantener un alto rendimiento y tiempos de respuesta rápidos, incluso cuando su huella de datos se amplía.
Hemos de pensar en la fragmentación de bases de datos como en una distribución de pesos. Supongamos que alguien tiene que subir varias maletas por las escaleras y, en total, pesan 45 kilos. Aunque es más que posible que algunas personas lleven sus propias maletas, otras tendrán problemas. Dividir las maletas entre varias personas significa que todos pueden llevar una carga más ligera. Habrá mucha menos tensión, ya que ninguna persona tendrá que cargar con un peso tan grande.
Database sharding es algo parecido. Al compartir la carga, los servidores se ven sometidos a menos presión, lo que les permite trabajar de forma más eficiente a todos los implicados.

¿Por qué es importante la fragmentación de bases de datos para las empresas?
La fragmentación de bases de datos es vital para las empresas que manejan grandes volúmenes de datos y necesitan acceder a ellos de forma continua. Sin ella, un servidor puede funcionar con demasiada lentitud y provocar una experiencia frustrante para los usuarios.
De hecho, los usuarios notan que el ordenador se ralentiza cuando hay demasiados programas abiertos. Los servidores de bases de datos se enfrentan a un efecto similar cuando tienen demasiados datos y demasiadas personas intentando acceder a ellos. Este gran volumen de datos mezclado con una actividad intensa se traduce en un tiempo de respuesta más lento y, en el peor de los casos, en paradas del servidor.
¿Cuáles son las ventajas de la fragmentación de bases de datos?
La fragmentación de bases de datos es una forma inteligente de dividir la información para que las empresas puedan almacenar y acceder rápidamente a grandes cantidades de datos. He aquí otras ventajas específicas de una base de datos fragmentada.
Ampliar el negocio de forma más eficaz
Los fragmentos múltiples permiten escalar eliminando la preocupación de que la empresa se quede sin almacenamiento para su base de datos. Solo es necesario añadir más fragmentos a medida que se alcance el límite de datos, evitando así cuellos de botella o posibles cierres. También se puede sacar más partido a los servidores de bases de datos dividiendo los conjuntos de datos. De este modo, se reduce el riesgo de sobrecarga de un servidor concreto, al tiempo que se aportan más datos de forma continua.
Cómo mejorar el tiempo de respuesta de la base de datos
La ventaja más notable de una base de datos fragmentada es la mayor rapidez de respuesta. Otra metáfora útil es pensar en el sistema de gestión de bases de datos como si fuera una estantería.
Estamos en en una biblioteca intentando encontrar un libro concreto. ¿Qué es preferible, buscar en una estantería de mil libros o de cien? La fragmentación de bases de datos utiliza la misma cantidad de información, pero dividida en filas más pequeñas. Esta característica significa que el sistema de gestión de bases de datos puede recuperar información más rápidamente, lo que se traduce en una experiencia más rápida.
Evitar interrupciones del servicio
Demasiados datos procesados en poco tiempo pueden sobrecargar el sistema de gestión. Una de las consecuencias más comunes es la interrupción del servicio, que puede suponer horas o incluso días de pérdida de productividad empresarial.
Database sharding evita que esto ocurra, ya que reduce la carga del sistema y evita que se dependa demasiado de una única forma de almacenamiento. Esto significa que, aunque un fragmento deje de estar disponible de repente, los demás pueden seguir funcionando de forma independiente.
Funcionamiento de la fragmentación de bases de datos
Para entender cómo funciona la fragmentación de bases de datos, es útil pensar en los datos como una serie de estanterías organizadas. La base de datos almacena la información mediante una mezcla de filas y columnas denominada conjunto de datos.
Cuando estos fragmentos se distribuyen entre varios ordenadores se ha creado un nodo. Todos los fragmentos se dividen en varios nodos, aunque todos contienen la misma información sobre toda la base de datos. A continuación, el conjunto de datos se divide en fragmentos, una clave de fragmento y lo que se conoce como una arquitectura de no compartir nada.

Fragmentos
El término técnico para cada uno de los fragmentos de datos divididos es "fragmento lógico". El ordenador físico que almacena estos fragmentos lógicos se denomina "fragmento físico" o, a veces, "nodo de base de datos".
Se puede pensar en los fragmentos, o concretamente en los fragmentos lógicos, como en todos los libros de las estanterías de la base de datos. Cada una contiene información única y depende del usuario dónde y cómo almacenarlas.
Shard Key
Unos datos bien organizados son fundamentales para el buen funcionamiento de una empresa. Una shard key, o clave shard, es la forma de organizar adecuadamente los datos por tipo, reduciendo la pérdida de tiempo al tratar de encontrar los datos que se necesitan.
Cada conjunto de datos viene en columnas llenas de filas. Una clave de fragmento es la forma en que los desarrolladores deciden qué filas de cada conjunto de datos deben agruparse en un fragmento. Estas claves pueden proceder de columnas ya existentes o de otras nuevas. Seleccionar la clave de fragmentación correcta es crucial para la eficiencia de una base de datos fragmentada. Una clave de shard bien elegida garantiza que los datos se distribuyan uniformemente entre los shards, evitando que uno de ellos se convierta en un cuello de botella.
También ayuda a mantener el rendimiento de las consultas, ya que permite al sistema localizar rápidamente los shards pertinentes cuando se ejecuta una consulta. Las claves de fragmentos suelen basarse en datos de acceso frecuente o agrupados lógicamente, como ID de clientes, regiones geográficas o marcas de tiempo.
Al agrupar datos relacionados, las claves de fragmentos pueden mejorar las operaciones de lectura y escritura, haciendo más eficiente la recuperación y gestión de datos. Sin embargo, elegir una clave de fragmentación inadecuada puede provocar una distribución desigual de los datos, un aumento de la carga en determinados nodos y, en última instancia, degradar el rendimiento.
Arquitectura compartida
Una arquitectura shared-nothing (SN) es un sistema de gestión de bases de datos que funciona con varias partes independientes. Esto significa que cada fragmento físico que se crea solo funcionará con los datos que contenga, no se podrán extraer datos de otro fragmento físico.
Sin embargo, es posible crear un sistema de fragmentos en el que varios de ellos puedan extraer datos de otras fuentes. Crear una capa de software es una forma de coordinar el almacenamiento de datos y proporcionar acceso a varios fragmentos a la vez.

¿Cuáles son los inconvenientes de la fragmentación?
Aunque la fragmentación es una forma increíblemente eficaz de mejorar los tiempos de respuesta y el acceso compartido, sigue habiendo inconvenientes. El tamaño de la empresa y la frecuencia con la que recupera grandes volúmenes de datos determinarán si la fragmentación es el método adecuado para ella.
Mayores costes de infraestructura
La fragmentación de bases de datos aumenta significativamente los costes de infraestructura debido a la necesidad de múltiples servidores o nodos para distribuir los datos. Esta multiplicación del hardware no sólo eleva los gastos iniciales de equipamiento, sino que también conlleva mayores costes corrientes de consumo eléctrico, espacio en el centro de datos y redes.
Además, la complejidad de gestionar un sistema fragmentado suele requerir más personal cualificado o formación adicional, lo que incrementa aún más los costes operativos. Este aumento de los gastos puede ser considerable. Pero para muchas empresas que manejan grandes volúmenes de datos, la mejora de la escalabilidad y el rendimiento puede justificar la inversión.
Mayor complejidad de la arquitectura de datos
Otro aspecto difícil de la fragmentación de bases de datos es el nivel de complejidad que añade a las operaciones empresariales. En lugar de gestionar una única base de datos, hay que dividir la atención entre varios shards (o nodos) físicos.
Las empresas más pequeñas que aún no necesitan grandes volúmenes de datos pueden considerar que el sharding es innecesariamente complejo. Sin embargo, las pequeñas empresas con planes para escalar se beneficiarían eventualmente de la fragmentación.
Distribución desigual de los datos
La distribución desigual de los datos entre los fragmentos es un reto importante en la fragmentación de bases de datos. Este desequilibrio puede provocar cuellos de botella en el rendimiento de los shards sobrecargados, desperdicio de recursos en los infrautilizados y una mayor complejidad en la gestión del sistema.
Cuando un shard se convierte en un "punto caliente" para las consultas, puede tener dificultades para mantener el ritmo de la demanda, lo que socava el objetivo principal de la fragmentación: distribuir la carga uniformemente para obtener un rendimiento óptimo.
Sin embargo, los sistemas de bases de datos avanzados suelen ofrecer funciones de equilibrio automático. Estos sistemas pueden detectar una distribución desigual y redistribuir los datos entre los shards para mantener el equilibrio, garantizando un rendimiento constante y una utilización eficiente de los recursos sin intervención manual.
Elegir el sistema de base de datos adecuado, como por ejemplo InterSystems IRIS es crucial para mitigar estos retos. Estos sistemas tienen equilibradores integrados que pueden vigilar las cargas de los fragmentos y cambiar automáticamente dónde se almacenan los datos. Esto permite que el usuario se centre en el uso de los datos en lugar de gestionar cómo se distribuyen.

¿Cuáles son los principales métodos de fragmentación de bases de datos?
La fragmentación de bases de datos es fundamentalmente flexible, ya que ofrece a las empresas un mayor control sobre los datos y la forma en que se organizan. Sin embargo, hay algunos métodos principales que deben tenerse en cuenta antes de empezar.
Fragmentación por rangos
También conocida como fragmentación dinámica, la fragmentación basada en rangos divide las filas de la base de datos en función de su valor. Cualquier rango que decida utilizarse se convierte en una clave de fragmento para un acceso rápido y sencillo.
Por ejemplo, si se decide dividir a los clientes por su sector, se puede utilizar una clave de fragmento para encontrarlos rápidamente en la base de datos. La aplicación que se utilice clasificará y almacenará automáticamente la información del cliente en un nodo específico. También se puede realizar una búsqueda inversa si se necesita encontrar un registro aún más específico.
La fragmentación basada en rangos es fácil de implementar y reproduce fielmente el trabajo con una hoja de cálculo de datos bien organizados. Sin embargo, es fácil sobrecargar accidentalmente demasiados datos en un nodo.
Caso práctico: la fragmentación basada en rangos es idónea para plataformas de comercio electrónico que clasifican los productos por rangos de precios o a los clientes por fechas de registro. También es adecuado para aplicaciones financieras que gestionan transacciones dentro de intervalos de fechas específicos.
Fragmentación Hashed
Cuando se desea contar con un nivel de control más ajustado sobre los detalles más pequeños, es recomendable recurrir a la fragmentación en hash. Este método de fragmentación funciona asignando una clave de fragmentación a una fila específica de la base de datos mediante una "función hash".
La función hash toma automáticamente la información de la fila designada y crea un "valor hash". Este valor hash funciona como la clave shard y almacena información sobre el fragmento físico que el usuario elija.
Es preferible la fragmentación hash por como distribuye uniformemente los datos entre fragmentos físicos, lo que reduce el riesgo de sobrecargar una máquina específica. Sin embargo, no puede distinguir la información basada en un significado más profundo, por lo que habrá que mantener la supervisión en el proceso. La fragmentación en hash es especialmente útil para plataformas de redes sociales o grandes aplicaciones web donde los datos de los usuarios deben repartirse uniformemente para evitar que un servidor esté demasiado ocupado.
Almacenamiento en directorios
Otra forma de fragmentación similar a una hoja de cálculo es la fragmentación de directorios. Este método proporciona una tabla de consulta que permite vincular las columnas de la base de datos a las claves de los fragmentos. Cualquier aplicación que almacene información basada en un detalle específico, como el color o la fecha, consulta primero la tabla de consulta.
La fragmentación de directorios es popular entre los gestores de bases de datos por la eficacia con la que organiza la información basada en detalles importantes. No hay límite de alcance y cada fragmento aporta más significado más allá de los números. El único inconveniente es la posibilidad de una organización errónea si la tabla de búsqueda contiene información inexacta.
Caso práctico: la fragmentación de directorios es muy adecuada para los sistemas de gestión de contenidos (CMS) o los sistemas de gestión de inventarios, donde es necesario encontrar rápidamente los elementos en función de atributos específicos como la categoría o la etiqueta.
Geo-Sharding
Este método de fragmentación es crucial para las empresas que reúnen un gran volumen de datos geográficos. La fragmentación geográfica divide la información por detalles como pueblo, ciudad, distrito o barrio.
Este método de fragmentación también tiene una ventaja basada en la ubicación de los fragmentos físicos. Una ciudad o pueblo concreto puede actuar como clave de un fragmento, almacenando la información del cliente en función de su proximidad a un fragmento físico. Con este método se consiguen tiempos de respuesta más rápidos. Dicho esto, las ventajas de la fragmentación geográfica sólo funcionan si hay una distancia física más corta entre el cliente y el fragmento físico. También existe el riesgo de que los datos se distribuyan de forma desigual si hay más clientes en una zona que en otra.
Caso práctico: la fragmentación geográfica es adecuada para servicios logísticos y de entrega, aplicaciones de transporte compartido o cualquier aplicación en la que la experiencia del usuario dependa de un acceso localizado y de baja latencia a los datos.
Fragmentación basada en relaciones
También conocida como fragmentación basada en entidades, la fragmentación basada en relaciones agrupa datos similares en el mismo fragmento físico. Este método es único con respecto a otras aplicaciones de fragmentación, ya que no es necesario separar tantos datos.
Como resultado, la fragmentación basada en relaciones reduce la potencia de cálculo necesaria para recuperar conjuntamente datos similares. Su principal inconveniente es su complejidad y la posibilidad de agrupar accidentalmente datos disímiles.
Caso práctico: la fragmentación basada en relaciones es perfecta para los sistemas de gestión de relaciones con los clientes (CRM) o cualquier aplicación que se beneficie de agrupar entidades relacionadas, como pedidos y clientes, o productos y categorías, para mejorar el rendimiento de las consultas y reducir el tiempo de recuperación.

Cómo fragmentar una base de datos
La fragmentación de una base de datos no es tan complicada como parece. Al igual que cuando se crea una nueva hoja de cálculo, hay que averiguar cuál es el objetivo final y cómo puede ayudarle a conseguirlo la fragmentación.
¿Cómo organizar información específica de forma más eficaz? ¿Cómo acelerar los tiempos de respuesta para los clientes que viven más cerca de los fragmentos físicos? Independientemente del método de fragmentación que se elija, hay un proceso específico para empezar:
- Eligir el esquema de fragmentación: pregúntarse sobre los datos que se están dividiendo ¿Por qué se quieren dividir estos datos y cómo?
- Determinar el método de la organización: aunque existen muchos métodos de fragmentación, conviene considerar la posibilidad de elegir uno de los métodos comunes mencionados anteriormente.
- Elegir la infraestructura de destino: delimitar los servidores en los que se crearán los fragmentos y realizar una estimación de la cantidad de datos que se almacenarán.
- Crear una capa de enrutamiento única: se debe determinar cómo se almacenarán los datos en la aplicación y cómo se consultarán posteriormente.
Ejecutar el plan de migración: por último, hay que decidir cómo se va a migrar toda esta información con un tiempo de inactividad mínimo. Muchas soluciones modernas de gestión de datos agilizan este proceso incorporándolo a la oferta de software.
¿Cuáles son las alternativas a la fragmentación de bases de datos?
Existen otras formas de organizar, almacenar y recuperar la información. Aunque la fragmentación de bases de datos se está convirtiendo rápidamente en el método preferido para las grandes empresas, también es posible probar lo siguiente.
Fragmentación frente a escalado vertical
Si, simplemente, se necesitan tiempos de respuesta más rápidos, puede considerarse la posibilidad de optimizar las operaciones de la empresa con el escalado vertical. Este sencillo enfoque simplemente añade más RAM o CPU al servidor de base de datos para gestionar más tráfico.
Esta opción es menos costosa que la fragmentación de bases de datos, aunque tampoco ofrece la misma flexibilidad a la hora de organizar los datos.
Fragmentación frente a replicación
La replicación es una forma más tradicional de organizar la base de datos. A diferencia del algoritmo personalizado de fragmentación de bases de datos, la replicación duplica copias exactas de la base de datos y las almacena en servidores independientes.
Dado que la fragmentación de bases de datos no crea copias de la información, la replicación puede ser más adecuada para según qué modelos de negocio. Puede que la organización esté más preocupada por perder los datos que por organizarlos.
Fragmentación frente a partición
Por último, la partición es un método que divide una tabla de base de datos en diferentes grupos. La partición horizontal divide los datos en filas, mientras que la partición vertical divide los datos en columnas.
Database sharding es similar, ya que también divide los datos en diferentes grupos con filas únicas. Sin embargo, almacena esta información en diferentes nodos. La partición divide esta información en el mismo ordenador.
¿Es necesaria la fragmentación de bases de datos?
La fragmentación de bases de datos es una forma increíblemente útil de reducir el tiempo de inactividad y organizar la información de forma más eficaz. Sin embargo, conlleva una curva de aprendizaje y puede resultar demasiado compleja para algunos modelos de negocio.Una cosa es segura: las empresas que quieren crecer necesitan tener una estrategia planificada sobre cómo almacenan y distribuyen los datos. Más del 90 % de las organizaciones que participaron en una encuesta reciente consiguieron un valor medible tras una inversión basada en datos. Tanto si se quiere ahorrar tiempo en la recuperación de datos como si preocupa sobrecargar el servidor, optimizar la base de datos tendrá beneficios en el futuro.
Cómo InterSystems IRIS puede ayudar con la fragmentación de bases de datos
No es necesario que una organización resuelva la distribución de los datos por sí misma. InterSystems IRIS incorpora diversas herramientas que contribuyen a escalar el negocio.
Una de las características que distinguen la tecnología de InterSystems IRIS es su notable flexibilidad de escalado. Tanto si es necesario añadir más recursos a un único servidor, como si lo es mediante la distribución de los datos entre varios servidores, InterSystems IRIS se adapta a las necesidades de la organización.
Esta flexibilidad permite empezar poco a poco e ir ampliando la infraestructura de bases de datos en función de los requisitos de la empresa, sin necesidad de grandes revisiones o migraciones.
InterSystems IRIS también ofrece transiciones fluidas entre distintos enfoques de escalado. Puede cambiar fácilmente del escalado vertical al horizontal a medida que aumentan los volúmenes de datos, garantizando que el rendimiento de la base de datos siga el ritmo de crecimiento del negocio.
Esta escalabilidad, combinada con la distribución inteligente de datos y las funciones de equilibrio automático de InterSystems IRIS, lo convierten en la opción idónea para empresas de todos los tamaños que buscan una infraestructura de datos preparada para el futuro.