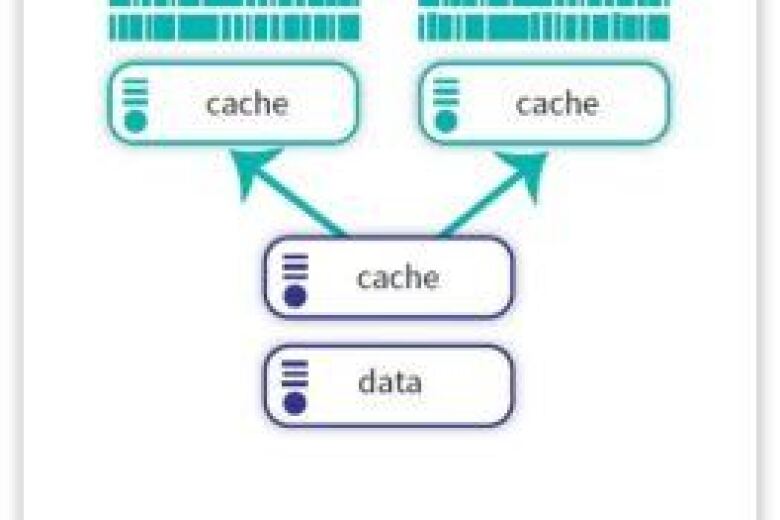
Chaque shard est stocké sur un serveur de base de données distinct, ce qui améliore les performances, la scalabilité et la disponibilité. Cette approche permet de répartir la charge et d’éviter qu’un seul serveur ne devienne un goulot d’étranglement, garantissant ainsi une gestion efficace de volumes de données plus importants et d’un nombre accru de transactions.
Chaque shard fonctionne de manière indépendante, tout en faisant partie d’un système de base de données logique unifié. De plus, le sharding renforce la tolérance aux pannes en isolant les défaillances à un shard spécifique, permettant ainsi au reste du système de continuer à fonctionner sans interruption.
Dans cet article, nous explorerons les avantages du sharding, sa comparaison avec d’autres approches d’organisation des bases de données, ainsi que son rôle dans la sécurisation et l’accessibilité des données.
Points clés à retenir
- Le sharding des bases de données améliore le temps de réponse, l’organisation et la scalabilité des entreprises.
- Cette approche peut cependant entraîner une complexité accrue et des coûts de maintenance plus élevés.
- Une distribution efficace des données devient un élément essentiel pour les entreprises à l’avenir.Le sharding des bases de données améliore le temps de réponse, l'organisation et la mise à l'échelle des entreprises.
Introduction au sharding des bases de données
Il est bien connu que les entreprises font face à une explosion sans précédent du volume de données. La quantité, la vitesse et la diversité des informations que les organisations doivent traiter et analyser augmentent à un rythme exponentiel chaque année.
Selon les recherches, la quantité de données créées et répliquées dans le monde devrait presque doubler entre 2021 et 2025, atteignant un impressionnant total de 181 zettaoctets (soit 181 milliards de téraoctets). Cet afflux massif de données représente à la fois une opportunité et un défi. D’un côté, il offre un accès à des insights plus approfondis et permet une prise de décision plus éclairée. De l’autre, il exerce une pression considérable sur les systèmes de bases de données. Avec l’augmentation des volumes de données, les architectures traditionnelles ont souvent du mal à suivre, entraînant des requêtes plus lentes, une baisse des performances et un risque accru de défaillances.
C’est là que le sharding des bases de données intervient. En répartissant les données sur plusieurs serveurs, cette technique permet aux entreprises de faire évoluer horizontalement leurs bases de données et ainsi de répondre aux exigences croissantes en matière de gestion des données. Grâce au sharding, elles peuvent maintenir des performances élevées et des temps de réponse rapides, même lorsque leur volume de données augmente de façon significative.
On peut comparer le sharding à la répartition d’un poids entre plusieurs personnes. Imaginez que vous deviez monter un escalier en portant plusieurs sacs pesant au total 50 kg. Certaines personnes pourraient réussir à les transporter seules, mais d’autres auraient du mal. Si l’on répartit les sacs entre plusieurs personnes, la charge est allégée pour chacun, réduisant ainsi la fatigue et rendant l’ensemble de l’opération plus efficace.
Le sharding fonctionne de la même manière : en partageant la charge entre plusieurs serveurs, il réduit la pression sur chacun d’eux, leur permettant ainsi de fonctionner plus efficacement et de mieux répondre aux besoins des utilisateurs.

Pourquoi le sharding des bases de données est-il important pour les entreprises ?
Le sharding des bases de données est essentiel pour les entreprises qui gèrent de grands volumes de données et doivent y accéder en continu. Sans sharding, un serveur peut devenir trop lent, entraînant une expérience frustrante pour les utilisateurs.
Avez-vous déjà remarqué que votre ordinateur ralentit lorsque trop de programmes sont ouverts simultanément ? Les serveurs de bases de données subissent un effet similaire lorsqu’ils doivent gérer une trop grande quantité de données et un trop grand nombre d’utilisateurs en même temps. Ce mélange entre un volume de données élevé et une forte activité entraîne un ralentissement des temps de réponse, voire, dans les pires scénarios, des interruptions de service.
Quels sont les avantages du sharding des bases de données ?
Le sharding est une approche efficace pour diviser l’information, permettant aux entreprises de stocker et d’accéder rapidement à de vastes quantités de données. Voici quelques-uns des principaux bénéfices d’une base de données shardée.
Améliorer l'évolutivité de votre entreprise
Si vous craignez de manquer d’espace de stockage dans votre base de données, le sharding vous permet d’ajouter facilement de nouveaux fragments (shards) au fur et à mesure que votre volume de données augmente. Cela évite les goulots d’étranglement et réduit le risque de pannes. En répartissant les ensembles de données sur plusieurs shards, vous réduisez également la surcharge d’un serveur unique, tout en assurant une collecte continue des données.
Optimiser le temps de réponse de votre base de données
L’un des principaux avantages du sharding est l’amélioration des temps de réponse. Pour illustrer cela, imaginez que votre base de données fonctionne comme une bibliothèque.
Si vous cherchez un livre spécifique, préférez-vous fouiller dans une étagère contenant mille ouvrages ou dans une autre qui n’en contient que cent ? Le sharding applique ce principe en divisant les données en segments plus petits, ce qui permet au système de gestion de base de données d’effectuer des recherches et des requêtes plus rapidement.
Éviter une interruption de service
Un trop grand volume de données traité en peu de temps peut surcharger un système de gestion de base de données. L’une des conséquences les plus courantes est une panne de service, pouvant entraîner des heures, voire des jours, de perte de productivité pour l’entreprise.
Le sharding prévient ce risque en réduisant la pression sur le système et en évitant une dépendance excessive à une seule source de stockage. Ainsi, même si un shard devient soudainement indisponible, les autres shards peuvent continuer à fonctionner indépendamment.
Comment fonctionne le sharding des bases de données
Pour mieux comprendre le fonctionnement du sharding, imaginez vos données comme une série d’étagères organisées. Une base de données stocke l’information sous forme de lignes et de colonnes regroupées dans un ensemble de données (dataset).
Lorsque ces shards sont répartis sur plusieurs serveurs, ils forment un nœud. Tous les shards sont distribués entre plusieurs nœuds, mais chaque nœud contient des informations permettant de reconstruire la base de données complète. L’ensemble des données est ensuite organisé en shards, à l’aide d’une clé de sharding, et repose sur une architecture dite "shared-nothing", où chaque shard fonctionne de manière autonome sans partage de ressources avec les autres.

Shards (Fragments de données)
Le terme technique pour désigner chaque segment de données divisé est un "shard logique". L’ordinateur physique qui stocke ces shards logiques est appelé "shard physique" ou parfois "nœud de base de données".
Vous pouvez considérer les shards – et plus précisément les shards logiques – comme les différents livres présents sur les étagères de votre base de données. Chacun contient des informations uniques, et c’est à vous de décider où et comment vous souhaitez les stocker
Clé de sharding
Une organisation efficace des données est essentielle pour assurer le bon fonctionnement d’une entreprise. Une clé de sharding permet d’organiser les données par type, évitant ainsi la perte de temps liée à la recherche des informations nécessaires.
Chaque ensemble de données est structuré sous forme de colonnes contenant des lignes. Une clé de sharding permet aux développeurs de déterminer quelles lignes d’un dataset doivent être regroupées au sein d’un même shard. Ces clés peuvent être basées sur des colonnes existantes ou être créées spécifiquement à cet effet.
Le choix de la clé de sharding est crucial pour garantir l’efficacité de la base de données shardée. Une clé bien choisie assure une répartition équilibrée des données entre les shards, évitant ainsi qu’un seul shard ne devienne un goulet d’étranglement.
Elle joue également un rôle clé dans la performance des requêtes, car elle permet au système de localiser rapidement les shards pertinents lors de l’exécution d’une requête. Les clés de sharding sont souvent basées sur des données fréquemment utilisées ou regroupées logiquement, comme des identifiants clients, des régions géographiques ou des horodatages.
En regroupant des données connexes, les clés de sharding optimisent les opérations de lecture et d’écriture, rendant la gestion et la récupération des données plus efficaces. En revanche, une mauvaise clé de sharding peut entraîner une répartition déséquilibrée des données, une surcharge de certains nœuds et, au final, une dégradation des performances.
Architecture "Shared-Nothing" (Sans partage de ressources)
Une architecture shared-nothing est un système de gestion de base de données qui fonctionne avec plusieurs composants indépendants. Cela signifie que chaque shard physique ne peut traiter que les données qu’il contient – il ne peut pas accéder aux données d’un autre shard physique.
Cependant, il est possible de concevoir un système de sharding où plusieurs shards peuvent accéder à d’autres sources de données. L’ajout d’une couche logicielle d’orchestration permet de coordonner le stockage des données et d’offrir un accès simultané à plusieurs shards.

Quels sont les inconvénients du sharding ?
Bien que le sharding soit une méthode extrêmement efficace pour améliorer les temps de réponse et l’accès partagé aux données, il présente également des inconvénients. La taille de votre entreprise et la fréquence à laquelle vous traitez de gros volumes de données détermineront si cette approche vous convient.
Des coûts d'infrastructure plus élevés
Le sharding des bases de données entraîne une augmentation significative des coûts d’infrastructure, car il nécessite plusieurs serveurs ou nœuds pour répartir les données. Cette multiplication des équipements entraîne non seulement des dépenses initiales plus importantes, mais également des coûts récurrents plus élevés liés à la consommation d’énergie, à l’espace dans les centres de données et à la mise en réseau.
De plus, la gestion d’un système shardé est plus complexe et peut nécessiter du personnel qualifié ou des formations supplémentaires, ce qui augmente encore les coûts opérationnels. Ces dépenses peuvent être conséquentes, mais pour de nombreuses entreprises manipulant de grands volumes de données, l’amélioration de la scalabilité et des performances justifie cet investissement.
Complexité accrue de l'architecture des données
Un autre inconvénient du sharding est la complexité supplémentaire qu’il apporte aux opérations de gestion des données. Plutôt que de gérer une base de données unique, vous devez répartir votre attention entre plusieurs shards physiques (ou nœuds).
Les petites entreprises qui ne traitent pas encore de gros volumes de données peuvent trouver le sharding inutilement complexe. Cependant, celles qui prévoient de se développer à l’avenir pourraient en tirer profit à long terme.
Distribution inégale des données
L’un des défis majeurs du sharding est la répartition inégale des données entre les shards. Ce déséquilibre peut entraîner des goulets d’étranglement sur les shards surchargés, un gaspillage de ressources sur ceux sous-utilisés et une complexité accrue dans la gestion du système.
Lorsqu’un shard devient un point chaud pour les requêtes, il peut avoir du mal à répondre à la demande, compromettant ainsi l’objectif principal du sharding : répartir la charge de manière homogène pour garantir des performances optimales.
Cependant, les systèmes de bases de données avancés offrent souvent des fonctionnalités d’équilibrage automatique. Ces systèmes détectent les déséquilibres et redistribuent les données entre les shards pour maintenir un bon équilibre, assurant ainsi des performances constantes et une utilisation efficace des ressources sans intervention manuelle.
Le choix du bon système de gestion de bases de données, comme InterSystems IRIS , est essentiel pour atténuer ces défis. Ces solutions intègrent des mécanismes de répartition automatique qui surveillent la charge des shards et ajustent dynamiquement l’emplacement des données. Ainsi, vous pouvez vous concentrer sur l’exploitation de vos données plutôt que sur leur gestion technique.

Quelles sont les principales méthodes de partage des bases de données ?
Le sharding des bases de données est une approche flexible qui permet aux entreprises de mieux contrôler et organiser leurs données. Cependant, il existe plusieurs méthodes principales à examiner avant de se lancer.
Sharding basé sur des plages de valeurs
Également appelé sharding dynamique, ce type de sharding divise les lignes d’une base de données en fonction de leur valeur. La plage que vous définissez devient une clé de sharding qui permet un accès rapide et simplifié aux données.
Par exemple, si vous choisissez de segmenter vos clients en fonction de leur secteur d’activité, vous pouvez utiliser une clé de sharding pour les retrouver facilement dans la base de données. L’application que vous utilisez catégorisera et stockera automatiquement les informations du client sur un nœud spécifique. Vous pouvez également effectuer un matching inversé pour retrouver des enregistrements encore plus précis.
Le sharding par plage est facile à mettre en œuvre et fonctionne de manière similaire à un tableur bien organisé. Cependant, il présente un risque : une mauvaise répartition des données peut surcharger un nœud.
Cas d'usage : Idéal pour les plateformes e-commerce qui classent les produits par gamme de prix ou les clients par date d’inscription. Convient aussi aux applications financières qui gèrent des transactions par plage de dates.
Sharding basé sur le hachage
Si vous souhaitez un contrôle plus granulaire sur les données, le sharding par hachage est une solution adaptée. Cette méthode fonctionne en attribuant une clé de sharding à une ligne spécifique de la base de données à l’aide d’une fonction de hachage.
Cette fonction prend automatiquement les informations de la ligne désignée et génère une valeur de hachage, qui est utilisée comme clé de sharding. Les données sont ensuite stockées sur le shard physique associé à cette valeur.
Le principal avantage du sharding par hachage est qu’il répartit les données de manière équilibrée sur tous les shards physiques, évitant ainsi la surcharge d’un serveur. Cependant, il ne prend pas en compte la signification des données, ce qui peut nécessiter une supervision manuelle. Cette méthode est particulièrement utile pour les réseaux sociaux ou grandes applications web, où les données des utilisateurs doivent être réparties uniformément pour éviter qu’un serveur ne soit saturé.
Sharding basé sur un annuaire
Le sharding par annuaire fonctionne de manière similaire à un tableur et utilise une table de correspondance pour lier les colonnes de la base de données aux clés de sharding. Toute application qui stocke des informations en fonction d’un détail spécifique (comme une couleur ou une date) consulte d’abord cette table.
Cette méthode est populaire parmi les gestionnaires de bases de données, car elle permet d’organiser efficacement les données selon des critères précis. Contrairement au sharding par plage, il n’y a pas de limite de plage, et chaque shard peut contenir des informations plus riches que de simples valeurs numériques.
Son principal inconvénient réside dans la gestion de la table de correspondance : si celle-ci contient des informations erronées, l’organisation des données peut être compromise.
Cas d'usage : Parfait pour les systèmes de gestion de contenu (CMS) ou les systèmes de gestion d’inventaire, où les articles doivent être rapidement retrouvés en fonction d’attributs spécifiques comme une catégorie ou un tag.
Sharding géographique
Le sharding géographique est crucial pour les entreprises qui collectent un grand volume de données géolocalisées. Il segmente les informations en fonction de critères tels que ville, région ou pays.
Cette méthode a l’avantage d’améliorer les performances en stockant les données à proximité de leurs utilisateurs. Une ville ou une région peut servir de clé de sharding, permettant de stocker les informations clients en fonction de leur emplacement. Cette approche réduit les temps de réponse, mais son efficacité dépend de la proximité physique entre l’utilisateur et le shard. De plus, un déséquilibre peut survenir si certaines zones géographiques contiennent beaucoup plus de clients que d’autres.
Cas d’usage : Idéal pour les services logistiques et de livraison, les applications de covoiturage, ou toute application où l’expérience utilisateur dépend d’un accès rapide aux données locales.
Sharding basé sur les relations
Aussi appelé sharding basé sur les entités, ce type de sharding regroupe des données similaires sur un même shard physique. Contrairement aux autres méthodes, il ne nécessite pas de fragmenter les données en profondeur.
En conséquence, il réduit la puissance de calcul nécessaire pour récupérer des ensembles de données connexes. Son principal inconvénient réside dans sa complexité : une mauvaise planification peut entraîner des regroupements de données incohérents.
Cas d’usage : Parfait pour les systèmes de gestion de la relation client (CRM) ou toute application qui bénéficie du groupement d’entités liées, comme les commandes et clients, ou les produits et catégories, afin d’améliorer les performances des requêtes et de réduire les temps d’accès.

Comment partitionner une base de données avec le sharding ?
Le sharding d’une base de données n’est pas aussi complexe qu’il y paraît. Tout comme la création d’un nouveau tableur, il suffit de définir son objectif final et d’identifier comment le sharding peut y contribuer.
Avez-vous besoin d'organiser des informations spécifiques de manière plus efficace ? Pourquoi ne pas accélérer les temps de réponse pour les clients qui habitent plus près des "shards" physiques ? Quelle que soit la méthode de sharding choisie, il existe un processus spécifique pour commencer :
- Choisissez votre schéma de sharding : Définissez le type de données à partitionner et pourquoi.
- Déterminez votre méthode d'organisation : Sélectionnez une approche parmi les méthodes courantes évoquées précédemment.
- Choisissez votre infrastructure cible : Identifiez les serveurs qui hébergeront les shards et estimez le volume de données à stocker.
- Créez une couche de routage unique : Déterminez comment l’application stockera et interrogera les données.
- Exécutez votre plan de migration : Mettez en place une stratégie de migration avec un minimum d’interruptions. Les solutions modernes de gestion des données automatisent souvent cette tâche.
Quelles sont les alternatives au sharding de base de données ?
Si le sharding est une solution courante pour les entreprises en pleine croissance, d’autres approches existent.
Sharding vs. Scalabilité verticale
Si votre besoin principal est d’améliorer les performances, la scalabilité verticale est une alternative. Elle consiste à ajouter plus de RAM ou de CPU à votre serveur de base de données pour gérer plus de trafic.
Moins coûteuse que le sharding, elle reste cependant limitée en termes d’organisation des données.
Sharding vs. Réplication
La réplication est une méthode plus ancienne qui duplique l’intégralité d’une base de données sur plusieurs serveurs, contrairement au sharding qui segmente les données.
Elle est plus adaptée aux entreprises cherchant à sécuriser leurs données plutôt qu’à les organiser.
Sharding vs. Partitionnement
Le partitionnement divise une table en plusieurs segments. Le partitionnement horizontal découpe les lignes, tandis que le partitionnement vertical découpe les colonnes. Contrairement au sharding, ces segments restent sur le même serveur.
Pourquoi adopter le sharding ?
Le sharding est une solution efficace pour réduire les temps d’arrêt et structurer les données. Cependant, il nécessite une expertise et peut être trop complexe pour certains modèles économiques.
90 % des organisations ayant investi dans la gestion de données ont constaté un gain mesurable. Que vous souhaitiez accélérer l'accès aux données ou éviter la surcharge d’un serveur, une optimisation de votre base de données sera un atout à long terme.
Comment InterSystems IRIS peut vous aider avec le sharding de bases de données ?
Vous n’avez pas à gérer seul la répartition des données. InterSystems IRIS met à votre disposition des outils avancés qui simplifient la mise en œuvre du sharding tout en accompagnant la croissance de votre entreprise.
Ce qui distingue InterSystems IRIS, c’est sa flexibilité exceptionnelle en matière de scalabilité. Que vous souhaitiez scaler verticalement en ajoutant des ressources à un serveur unique ou scaler horizontalement en répartissant les données sur plusieurs serveurs, InterSystems IRIS s’adapte à vos besoins.
Grâce à cette flexibilité, vous pouvez commencer avec une infrastructure modeste et la faire évoluer progressivement, sans nécessiter de refonte majeure ni de migration complexe.
InterSystems IRIS facilite également la transition entre différentes approches de mise à l’échelle. Vous pouvez aisément passer du scaling vertical au scaling horizontal à mesure que le volume de vos données augmente, garantissant ainsi des performances optimales en phase avec la croissance de votre activité.
Cette capacité de scalabilité, combinée à la distribution intelligente des données et aux fonctionnalités d’équilibrage automatique d’InterSystems IRIS, en fait une solution idéale pour les entreprises de toutes tailles souhaitant pérenniser leur infrastructure de données.