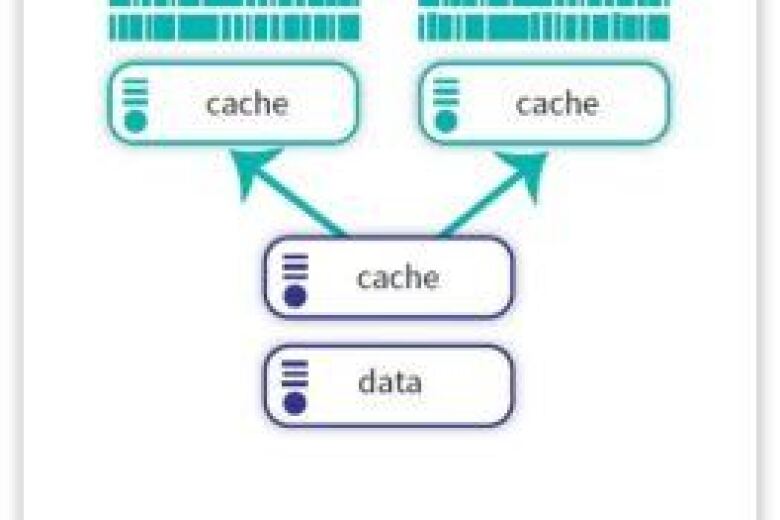
Lo sharding dei database è un modello di architettura di database in cui un grande insieme di dati viene suddiviso in parti più piccole e gestibili, chiamate "shard". Ogni shard è memorizzato su un server di database separato per migliorare le prestazioni, la scalabilità e la disponibilità.
Questo approccio aiuta a distribuire il carico e garantisce che nessun singolo server diventi un collo di bottiglia, consentendo al sistema di gestire in modo efficiente un maggior numero di dati e di transazioni. Ogni shard opera in modo indipendente, ma insieme formano un unico sistema logico di database. Inoltre, lo sharding dei database può migliorare la tolleranza ai guasti isolando i guasti ai singoli shard, consentendo al resto del sistema di continuare a funzionare senza problemi.
In questo post analizzeremo i vantaggi dello sharding dei database, il suo confronto con altri metodi di organizzazione dei database e il modo in cui aiuta a mantenere i dati sicuri e accessibili.
Punti di forza
- Lo sharding dei database migliora i tempi di risposta, l'organizzazione e la scalabilità delle aziende.
- A volte questo comporta una maggiore complessità e costi di manutenzione più elevati.
- La distribuzione efficace dei dati è una caratteristica imprescindibile per le aziende in futuro.
Introduzione allo sharding dei database
È risaputo che le aziende si trovano ad affrontare un'esplosione di dati senza precedenti. Il volume, la velocità e la varietà delle informazioni che le aziende devono elaborare e analizzare crescono ogni anno a un ritmo esponenziale.
Le ricerche mostrano che la quantità di dati creati e replicati a livello globale dovrebbe quasi raddoppiare tra il 2021 e il 2025, raggiungendo la strabiliante cifra di 181 zettabyte (ovvero 181 miliardi di terabyte). Questo massiccio afflusso di dati presenta sia opportunità che sfide. Se da un lato offre il potenziale per approfondimenti e decisioni più informate, dall'altro mette sotto pressione i sistemi di database. Quando i volumi di dati crescono, le architetture di database tradizionali spesso faticano a tenere il passo, con conseguenti tempi di interrogazione più lenti, prestazioni ridotte e potenziali guasti del sistema.
È qui che entra in gioco lo sharding dei database. Distribuendo i dati su più server, lo sharding consente alle aziende di scalare orizzontalmente i propri database, riuscendo a tenere il passo con le richieste di dati in costante aumento. Consente alle aziende di mantenere prestazioni elevate e tempi di risposta rapidi, anche quando l'ingombro dei dati si espande.
Considerate lo sharding dei database come una distribuzione di pesi. Supponiamo di dover portare su per una rampa di scale diverse borse che pesano complessivamente un centinaio di chili. Mentre per alcune persone è più che possibile trasportare le borse da sole, altre avranno problemi. Dividere le borse tra più persone significa che tutti possono portare un carico più leggero. Ci saranno molte meno tensioni, poiché nessuna persona dovrà sostenere un peso così grande.
Il database sharding è più o meno la stessa cosa. La condivisione del carico riduce la pressione sui server, liberandoli per lavorare in modo più efficiente per tutti i soggetti coinvolti.

Perché lo sharding dei database è importante per le aziende?
Lo sharding dei database è fondamentale per le aziende che gestiscono grandi volumi di dati e hanno bisogno di accedervi in modo continuo. Senza sharding del database, un server potrebbe funzionare troppo lentamente e causare un'esperienza frustrante per gli utenti.
Avete mai notato che il vostro computer rallenta quando avete troppi programmi aperti? I server di database subiscono un effetto simile quando hanno troppi dati e troppe persone che cercano di accedervi. Questo grande volume di dati, unito a un'attività elevata, comporta un rallentamento dei tempi di risposta e, nel peggiore dei casi, l'arresto del server.
Quali sono i vantaggi dello sharding dei database?
Lo sharding dei database è un modo intelligente di dividere le informazioni in modo che le aziende possano archiviare e accedere rapidamente a grandi quantità di dati. Ecco altri vantaggi specifici di un database sharded.
Scalare il business in modo più efficiente
Se vi siete mai preoccupati di esaurire lo spazio di archiviazione del database, più shard vi permettono di scalare. È possibile aggiungere altri shard man mano che si raggiunge il limite di dati, evitando colli di bottiglia o possibili arresti. È inoltre possibile sfruttare meglio i server di database dividendo i set di dati. In questo modo si riduce il rischio di sovraccaricare un server specifico, pur continuando a fornire più dati su base continuativa.
Migliorare il tempo di risposta del database
Il vantaggio più evidente di un database sharded è la maggiore velocità di risposta. Un'altra metafora utile è quella di pensare al sistema di gestione del database come a uno scaffale.
Immaginate di essere in una biblioteca e di cercare un libro specifico. Preferireste cercare in uno scaffale con mille libri o con cento? Lo sharding del database utilizza la stessa quantità di informazioni, ma è suddiviso in righe più piccole. Questa caratteristica consente al sistema di gestione dei database di recuperare le informazioni più rapidamente, rendendo l'esperienza più veloce.
Evitare un'interruzione del servizio
Una quantità eccessiva di dati elaborati in un breve lasso di tempo può sovraccaricare il sistema di gestione dei database. Uno dei risultati più comuni è l'interruzione del servizio, con conseguente perdita di ore o addirittura giorni di produttività aziendale.
Lo sharding dei database evita che ciò accada, riducendo la pressione sul sistema e impedendo un'eccessiva dipendenza da un'unica forma di storage. Ciò significa che, anche se uno shard diventa improvvisamente indisponibile, gli altri shard possono continuare a lavorare in modo indipendente.
Come funziona lo sharding del database
Per capire come funziona lo sharding dei database, è utile pensare ai dati come a una serie di scaffali organizzati. Il database memorizza le informazioni utilizzando un insieme di righe e colonne chiamato dataset.
Quando si suddividono questi frammenti su più computer, si crea un nodo. Tutti gli shard sono suddivisi in più nodi, anche se contengono tutti le stesse informazioni sull'intero database. Il dataset viene quindi suddiviso in shard, una chiave shard e la cosiddetta architettura shared-nothing.

Partizioni
Il termine tecnico per ciascuno dei pezzi di dati divisi è "shard logico". Il computer fisico che memorizza questi shard logici è chiamato "shard fisico" o talvolta "nodo di database".
Si può pensare agli shard, o in particolare agli shard logici, come a tutti i diversi libri presenti sugli scaffali del database. Ognuno di essi contiene informazioni uniche e sta a voi decidere dove e come memorizzarli.
Shard key
Una buona organizzazione dei dati è la chiave per il buon funzionamento di un'azienda. Una shard key è il modo in cui si organizzano correttamente i dati per tipo, riducendo le perdite di tempo per trovare i dati necessari.
Ogni set di dati è composto da colonne piene di righe. Una shard key è il modo in cui gli sviluppatori decidono quali righe di ciascun set di dati devono essere raggruppate in uno shard. Queste shard key possono provenire da colonne esistenti o nuove. La scelta della giusta shard key è fondamentale per l'efficienza del database sharded. Una shard key ben scelta assicura che i dati siano distribuiti in modo uniforme tra gli shard, evitando che un singolo shard diventi un collo di bottiglia.
Contribuisce inoltre a mantenere le prestazioni delle query, in quanto consente al sistema di individuare rapidamente gli shard pertinenti quando viene eseguita una query. Le chiavi shard sono spesso basate su dati ad accesso frequente o raggruppati logicamente, come ID cliente, regioni geografiche o timestamp.
Raggruppando i dati correlati, le chiavi shard possono migliorare le operazioni di lettura e scrittura, rendendo più efficiente il recupero e la gestione dei dati. Tuttavia, la scelta di una shard key inadeguata può portare a una distribuzione non uniforme dei dati, a un aumento del carico su alcuni nodi e, in ultima analisi, a un peggioramento delle prestazioni.
Architettura shared-nothing
Un'architettura shared-nothing è un sistema di gestione di database che opera con diverse parti indipendenti. Ciò significa che ogni shard fisico creato opererà solo sui dati che contiene, senza poter prelevare dati da un altro shard fisico.
Tuttavia, è possibile creare un sistema di shard in cui più shard possono prelevare dati da altre fonti. La creazione di un livello software è un modo per coordinare l'archiviazione dei dati e fornire l'accesso a più shard contemporaneamente.

Quali sono gli svantaggi dello sharding?
Sebbene lo sharding sia un metodo incredibilmente efficace per migliorare i tempi di risposta e l'accesso condiviso, ci sono comunque degli svantaggi. Le dimensioni della vostra azienda e la frequenza con cui recuperate grandi volumi di dati determineranno se lo sharding è il metodo che fa per voi.
Costi infrastrutturali più elevati
Lo sharding dei database aumenta significativamente i costi dell'infrastruttura a causa della necessità di più server o nodi per distribuire i dati. Questa moltiplicazione dell'hardware non solo aumenta le spese iniziali per le apparecchiature, ma comporta anche un aumento dei costi correnti per il consumo di energia, lo spazio del data center e la rete.
Inoltre, la complessità della gestione di un sistema sharded spesso richiede personale più qualificato o una formazione aggiuntiva, con un ulteriore aumento dei costi operativi. L'aumento delle spese può essere notevole. Ma per molte aziende che hanno a che fare con grandi volumi di dati, il miglioramento della scalabilità e delle prestazioni può giustificare l'investimento.
Maggiore complessità dell'architettura dei dati
Un altro aspetto difficile dello sharding dei database è il livello di complessità che aggiunge alle operazioni aziendali. Invece di gestire un singolo database, si deve dividere l'attenzione tra più shard (o nodi) fisici.
Le piccole aziende che non hanno ancora bisogno di grandi volumi di dati possono trovare lo sharding inutilmente complesso. Tuttavia, le piccole imprese con piani di scalabilità potrebbero beneficiare dello sharding.
Distribuzione disomogenea dei dati
La distribuzione non uniforme dei dati tra gli shard è una sfida significativa nello sharding dei database. Questo squilibrio può portare a colli di bottiglia nelle prestazioni sugli shard sovraccarichi, a uno spreco di risorse su quelli sottoutilizzati e a una maggiore complessità nella gestione del sistema.
Quando uno shard diventa un "hot spot" per le query, può faticare a tenere il passo con la domanda, compromettendo l'obiettivo primario dello sharding: distribuire il carico in modo uniforme per ottenere prestazioni ottimali.
Tuttavia, i sistemi di database avanzati spesso offrono funzioni di bilanciamento automatico. Questi sistemi sono in grado di rilevare una distribuzione non uniforme e di ridistribuire i dati tra gli shard per mantenere l'equilibrio, garantendo prestazioni costanti e un utilizzo efficiente delle risorse senza interventi manuali.
La scelta del sistema di database giusto, come ad esempio InterSystems IRISè fondamentale per mitigare queste sfide. Questi sistemi dispongono di bilanciatori integrati in grado di osservare i carichi degli shard e di cambiare automaticamente la posizione dei dati. In questo modo è possibile concentrarsi sull'utilizzo dei dati invece di gestire la loro distribuzione.

Quali sono i principali metodi di sharding dei database?
Lo sharding dei database è fondamentalmente flessibile e offre alle aziende un maggiore controllo sui dati e sulla loro organizzazione. Tuttavia, ci sono alcuni metodi principali che dovreste esaminare prima di iniziare.
Range-Based Sharding
Conosciuto anche come sharding dinamico, lo sharding basato sull'intervallo (range-based sharding) divide le righe del database in base al loro valore. Qualsiasi intervallo si decida di utilizzare diventa una shard key per un accesso rapido e facile.
Ad esempio, se si decide di suddividere i clienti in base al loro settore, è possibile utilizzare una shard key per trovarli rapidamente nel database. L'applicazione utilizzata categorizzerà e memorizzerà automaticamente le informazioni del cliente su un nodo specifico. Si può anche fare una corrispondenza inversa se si vuole trovare un record ancora più specifico.
Lo sharding basato sugli intervalli è facile da implementare e riproduce fedelmente il lavoro con un foglio di calcolo di dati ben organizzati. Tuttavia, è facile sovraccaricare accidentalmente troppi dati su un solo nodo.
Caso d'uso pratico: lo sharding basato su intervalli è ideale per le piattaforme di e-commerce che categorizzano i prodotti per fasce di prezzo o i clienti per date di registrazione. È adatto anche alle applicazioni finanziarie che gestiscono le transazioni entro intervalli di date specifici.
Hashed Sharding
Quando si vuole ottenere un livello di controllo più fine sui dettagli più piccoli, si può ricorrere all'hashed sharding. Questo metodo di sharding funziona assegnando una chiave di shard a una riga specifica del database attraverso una "funzione hash".
La funzione hash prende automaticamente le informazioni dalla riga designata e crea un "valore hash". Questo valore hash funziona come chiave dello shard e memorizza le informazioni sullo shard fisico scelto.
Lo sharding con hash è preferito per il modo in cui distribuisce uniformemente i dati tra gli shard fisici, riducendo il rischio di sovraccaricare una macchina specifica. Tuttavia, non è in grado di distinguere le informazioni in base a un significato più profondo, quindi è necessario applicare una certa sorveglianza. Lo sharding hashed è particolarmente utile per le piattaforme di social media o per le applicazioni web di grandi dimensioni, dove i dati degli utenti devono essere distribuiti in modo uniforme per evitare che un server sia troppo occupato.
Directory Sharding
Un'altra forma di sharding simile a un foglio elettronico è lo sharding delle directory. Questo metodo accessibile fornisce una tabella di ricerca che consente di collegare le colonne del database alle chiavi di shard. Qualsiasi applicazione che memorizzi informazioni basate su un dettaglio specifico, come un colore o una data, fa riferimento prima alla tabella di lookup.
Lo sharding delle directory è popolare tra i gestori di database per l'efficacia con cui organizza le informazioni in base a dettagli importanti. Non c'è limite di portata e ogni frammento fornisce un significato che va oltre i numeri. L'unico inconveniente è la possibilità di un'organizzazione errata se la tabella di ricerca contiene informazioni imprecise.
Caso d'uso pratico: lo sharding delle directory è adatto ai sistemi di gestione dei contenuti (CMS) o ai sistemi di gestione dell'inventario in cui è necessario trovare rapidamente gli articoli in base ad attributi specifici come la categoria o il tag.
Geo-Sharding
Questo metodo di sharding è fondamentale per le aziende che raccolgono un grande volume di dati geografici. Il geo-sharding divide le informazioni in base a dettagli come città, quartiere o quartiere.
Questo metodo di sharding presenta anche un vantaggio basato sulla posizione fisica degli shard. Una città o un paese specifico può fungere da chiave di shard, memorizzando le informazioni dei clienti in base alla loro vicinanza a uno shard fisico. Questo metodo consente di ottenere tempi di risposta più rapidi. Detto questo, i vantaggi del geo sharding funzionano solo se la distanza fisica tra il cliente e lo shard fisico è ridotta. C'è anche il rischio di una distribuzione non uniforme dei dati, se la quantità di clienti in un'area è maggiore rispetto a un'altra.
Caso d'uso pratico: il geo sharding è ideale per i servizi di logistica e consegna, per le app di ride-sharing o per qualsiasi applicazione in cui l'esperienza dell'utente dipende da un accesso ai dati localizzato e a bassa latenza.
Relationship-Based Sharding
Conosciuto anche come sharding basato sulle entità, lo sharding basato sulle relazioni raggruppa dati simili sullo stesso shard fisico. Questo metodo è unico rispetto alle altre applicazioni di sharding, poiché non è necessario separare una quantità di dati così elevata.
Di conseguenza, lo sharding basato sulle relazioni riduce la potenza di calcolo necessaria per recuperare insieme dati simili. Il suo principale svantaggio è la complessità e la possibilità di raggruppare accidentalmente dati dissimili.
Caso d'uso pratico: lo sharding basato sulle relazioni è perfetto per i sistemi di gestione delle relazioni con i clienti (CRM) o per qualsiasi applicazione che tragga vantaggio dal raggruppamento di entità correlate, come ordini e clienti o prodotti e categorie, per migliorare le prestazioni delle query e ridurre i tempi di recupero.

Come partizionare un database
Lo sharding di un database non è così complicato come sembra. Come per la creazione di un nuovo foglio di calcolo, è necessario capire qual è il vostro obiettivo finale e come lo sharding può aiutarvi a raggiungerlo.
Avete bisogno di organizzare informazioni specifiche in modo più efficace? Che ne dite di accelerare i tempi di risposta per i clienti che vivono più vicini agli shard fisici? Indipendentemente dal metodo di sharding scelto, esiste un processo specifico per iniziare:
- Scegliere lo schema di sharding: informarsi sui dati da suddividere. Perché volete dividere questi dati e come?
- Determinare il metodo di organizzazione: sebbene esistano molti metodi di sharding, si consiglia di scegliere tra quelli comuni indicati sopra.
- Scegliere l'infrastruttura di destinazione: restringere i server su cui creare gli shard e fare una stima della quantità di dati da archiviare.
- Creare un livello di routing unico: è necessario determinare come l'applicazione memorizzerà i dati e li interrogherà in seguito.
Eseguire il piano di migrazione: infine, è necessario decidere come migrare tutte queste informazioni con tempi di inattività minimi. Molte moderne soluzioni di gestione dei dati semplificano questo processo integrandolo nelle loro offerte software.
Quali sono le alternative allo sharding dei database?
Vi starete chiedendo se ci sono altri modi per organizzare, archiviare e recuperare le vostre informazioni. Sebbene lo sharding del database stia rapidamente diventando il metodo preferito dalle aziende più grandi, è possibile provare anche i seguenti metodi.
Sharding vs. scalatura verticale
Se avete semplicemente bisogno di tempi di risposta più rapidi, prendete in considerazione l'ottimizzazione delle operazioni aziendali con lo scaling verticale. Questo approccio semplice aggiunge semplicemente più RAM o CPU al server di database per gestire un traffico maggiore.
Questa opzione è meno costosa dello sharding del database, ma non offre la stessa flessibilità nell'organizzazione dei dati.
Sharding vs. replica
La replica è un modo più antiquato di organizzare il database. A differenza dell'algoritmo personalizzato di sharding dei database, la replica duplica copie esatte del database e le archivia su server separati.
Poiché lo sharding dei database non crea copie delle informazioni, la replica potrebbe essere più adatta al vostro modello aziendale. Potreste essere più preoccupati di perdere i vostri dati che di organizzarli.
Sharding vs. partizionamento
Infine, il partizionamento è un metodo che suddivide una tabella di database in diversi gruppi. Il partizionamento orizzontale divide i dati in righe, mentre quello verticale in colonne.
Lo sharding dei database è simile, poiché anch'esso divide i dati in gruppi diversi con righe uniche. Tuttavia, memorizza queste informazioni su diversi nodi. Il partizionamento divide queste informazioni sullo stesso computer.
Avete bisogno dello sharding del database?
Lo sharding dei database è un modo incredibilmente utile per ridurre i tempi di inattività e organizzare in modo più efficace le informazioni. Tuttavia, comporta una curva di apprendimento e potrebbe essere troppo complessa per alcuni modelli di business.
Una cosa è certa: le aziende che vogliono crescere devono avere una strategia intenzionale per l'archiviazione e la distribuzione dei dati.
Oltre il 90% delle organizzazioni in un recente sondaggio ha ottenuto un valore misurabile dopo un investimento basato sui dati. Sia che stiate cercando di risparmiare tempo nel recupero dei dati, sia che siate preoccupati di sovraccaricare il vostro server di database, l'ottimizzazione del vostro database darà i suoi frutti in futuro.
Come InterSystems IRIS può aiutarvi con lo sharding dei database
Non è necessario capire da soli la distribuzione dei dati. InterSystems IRIS vi offre diversi strumenti all'avanguardia per eliminare il lavoro pesante e aiutare la vostra azienda a scalare.
Ciò che distingue InterSystems IRIS è la sua notevole flessibilità di scalata. Sia che dobbiate scalare aggiungendo più risorse a un singolo server, sia che dobbiate scalare distribuendo i dati su più server, InterSystems IRIS si adatta alle vostre esigenze.
Questa flessibilità vi permette di iniziare in piccolo e di far crescere la vostra infrastruttura di database in linea con le vostre esigenze aziendali, senza dover effettuare grandi revisioni o migrazioni.
InterSystems IRIS offre anche transizioni senza soluzione di continuità tra diversi approcci di scalatura. È possibile passare facilmente dallo scaling verticale a quello orizzontale con l'aumentare dei volumi di dati, assicurando che le prestazioni del database tengano il passo con la crescita dell'azienda.
Questa scalabilità, unita alle funzioni di distribuzione intelligente dei dati e di bilanciamento automatico di InterSystems IRIS, lo rende la scelta ideale per le aziende di tutte le dimensioni che vogliono essere a prova di futuro per la loro infrastruttura di dati.